Graphic Card.
그래픽 카드 - 연도별 세대(Generation) 및 설계(Architecture)에 따른 특징들을 소개합니다.
 라데온 RX 7000 시리즈, 나비 3
(2022년 12월, Navi 3)
라데온 RX 7000 시리즈, 나비 3
(2022년 12월, Navi 3)
- 라데온 RX 7000 시리즈, 나비 3
 지포스 40 시리즈, 에이다 러브레이스
(2022년 10월, Ada Lovelace)
지포스 40 시리즈, 에이다 러브레이스
(2022년 10월, Ada Lovelace)
- 지포스 40 시리즈, 에이다 러브레이스
 아크 A 시리즈, 알케미스트
(2022년 4월, Alchemist)
아크 A 시리즈, 알케미스트
(2022년 4월, Alchemist)
- 아크 A 시리즈, 알케미스트
알케미스트 내용
라데온 RX 6000 시리즈, 나비 2
(2020년 12월, Navi 2)
- 라데온 RX 6000 시리즈, 나비 2
지포스 30 시리즈, 암페어
(2020년 9월, Ampere)
- 지포스 30 시리즈, 암페어
라데온 RX 5000 시리즈, 나비
(2019년 7월, Navi)
- 라데온 RX 5000 시리즈, 나비
지포스 20 / 16 시리즈, 튜링
(2018년 9월, Turing)
- 지포스 20 / 16 시리즈, 튜링
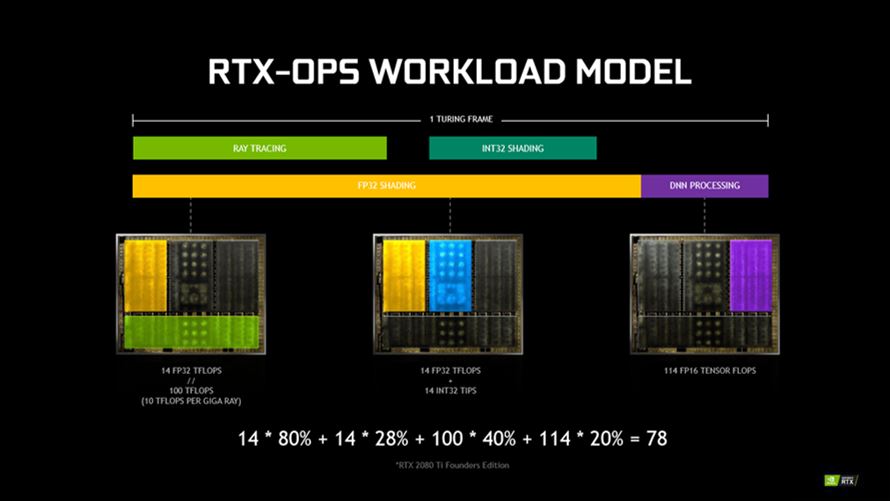
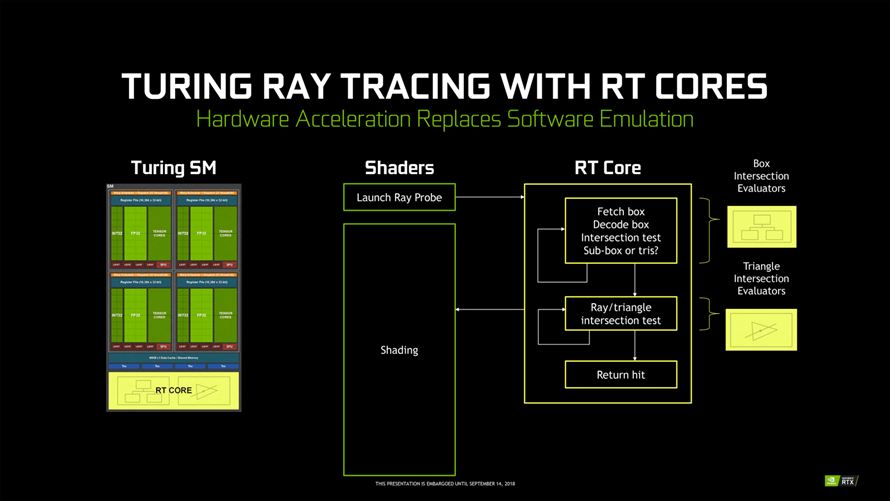
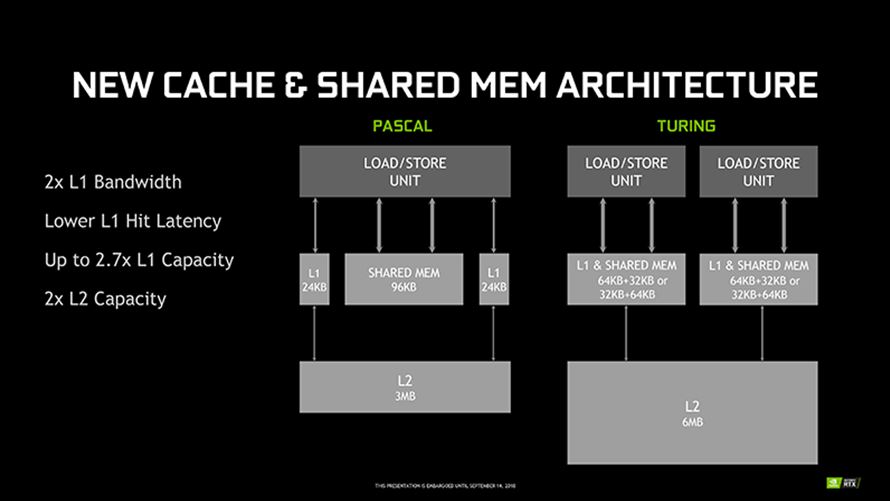
맥스웰과 파스칼로 기존 게이밍 그래픽의 정점을 달성한 엔비디아가 차세대 기술로 선택한 실시간 광원 추적(Ray Tracing, RT)에 초점을 맞춰 새롭게 개발된 GPU 입니다.
레이 트레이싱 기법은 직접 광원뿐만 아니라 객체에 반사되어 발생하는 간접 광원효과(n차)까지 반영해, 직접 광원효과(1차)에 비해 더욱 현실적인 표현이 가능합니다. 다만 광원을 추적하는 과정이 엄청난 처리량을 요구하기 때문에 실시간 렌더링 기반의 게임에 적용되지는 못했고, 정적 렌더링 및 영상 제작에만 주로 사용되어 왔습니다.
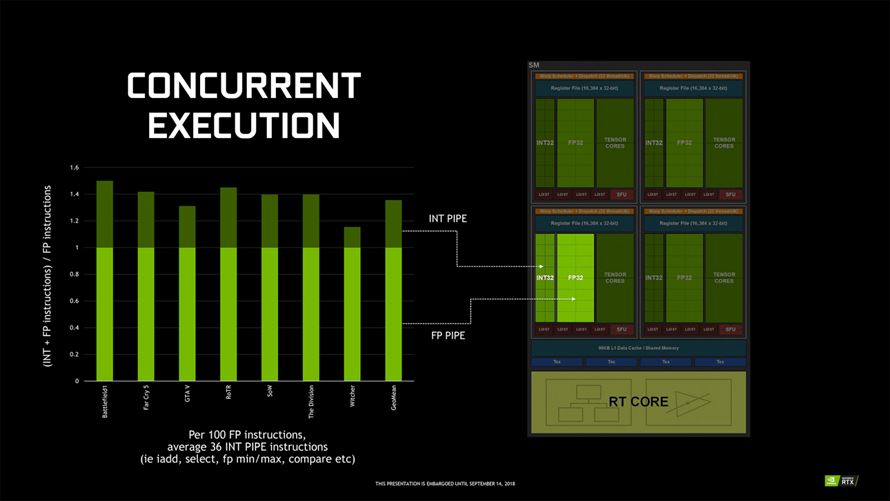
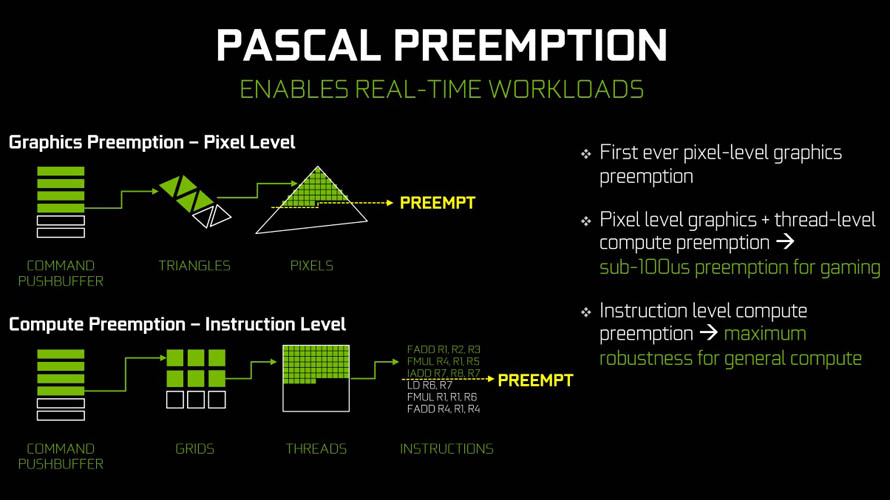
한편으로는 엔비디아의 원천 기술인 CUDA 코어에도 큰 변화가 있었습니다. 바로 정수(INT)와 부동 소수점(FP)의 역할이 명확하게 구분되었다는 점 입니다. 지금까지는 스트리밍 멀티프로세서(SM)에 투입되는 데이터의 우선 순위에 따라 번갈아가며 처리했지만(Pre-Emption), CUDA 코어의 역할이 분리되면서 정수와 부동 소수점을 동시에 수행(Concurrent) 할 수 있게 되었습니다.
SM마다 64개의 CUDA 코어가 정수(32개)와 부동 소수점(32개)으로 할당됩니다. 실질적인 그래픽 처리에 큰 영향을 미치는 부동 소수점 피크 효율은 32*4 구성이던 맥스웰/파스칼의 SM과 크게 다르지 않지만, 정수 연산이 부동 소수점 연산에 부담을 주지 않도록 개선되어 실제 게이밍 환경에서 더 나은 효율을 기대할 수 있습니다.
레이 트레이싱 기법은 직접 광원뿐만 아니라 객체에 반사되어 발생하는 간접 광원효과(n차)까지 반영해, 직접 광원효과(1차)에 비해 더욱 현실적인 표현이 가능합니다. 다만 광원을 추적하는 과정이 엄청난 처리량을 요구하기 때문에 실시간 렌더링 기반의 게임에 적용되지는 못했고, 정적 렌더링 및 영상 제작에만 주로 사용되어 왔습니다.

한편으로는 엔비디아의 원천 기술인 CUDA 코어에도 큰 변화가 있었습니다. 바로 정수(INT)와 부동 소수점(FP)의 역할이 명확하게 구분되었다는 점 입니다. 지금까지는 스트리밍 멀티프로세서(SM)에 투입되는 데이터의 우선 순위에 따라 번갈아가며 처리했지만(Pre-Emption), CUDA 코어의 역할이 분리되면서 정수와 부동 소수점을 동시에 수행(Concurrent) 할 수 있게 되었습니다.
SM마다 64개의 CUDA 코어가 정수(32개)와 부동 소수점(32개)으로 할당됩니다. 실질적인 그래픽 처리에 큰 영향을 미치는 부동 소수점 피크 효율은 32*4 구성이던 맥스웰/파스칼의 SM과 크게 다르지 않지만, 정수 연산이 부동 소수점 연산에 부담을 주지 않도록 개선되어 실제 게이밍 환경에서 더 나은 효율을 기대할 수 있습니다.
라데온 NCU 아키텍처, 베가
(2017년 8월, Vega)
- 라데온 NCU 아키텍처, 베가
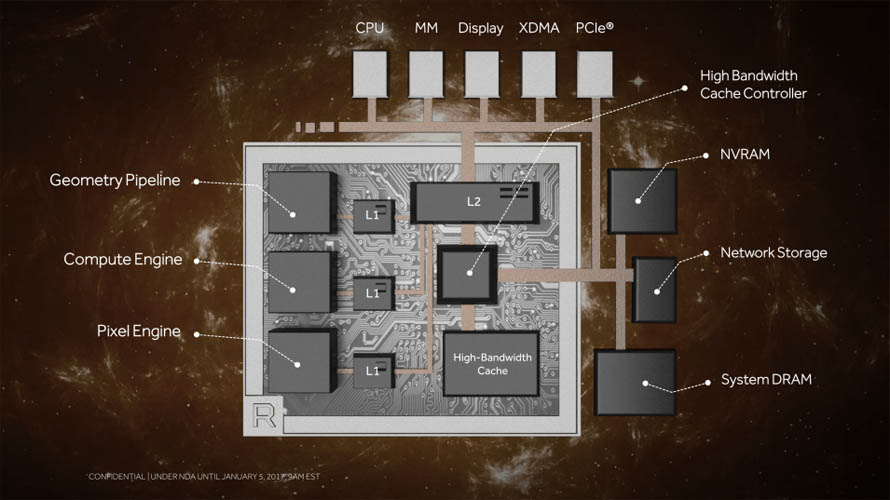
AMD 라데온 테크놀로지스 그룹(RTG)의 표현에 의하면 그래픽 코어 넥스트(GCN) 아키텍처의 뒤를 잇는 새로운 개념(Next Generation GPU)으로, 소비자 입장에서는 기존의 라데온 RX 400 / 500 시리즈(Polaris)의 상위 모델이라기 보다는 라데온 Fury / Pro Duo 시리즈(Fiji)의 후속 모델이라는 표현이 좀 더 현실적이라고 볼 수 있습니다.
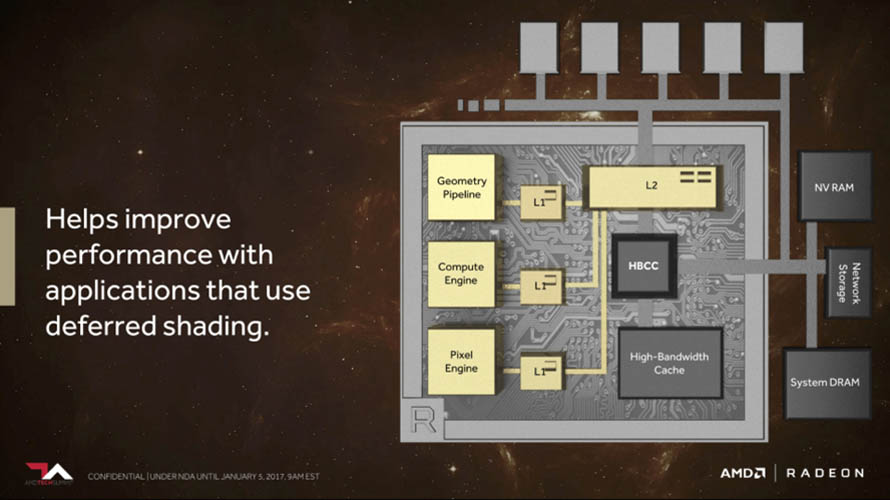
실제로 베가 아키텍처는 성능 외적으로 많은 면에서 기존 GPU 설계대비 차별화된 기능들이 대거 투입된 기념비적 라인업입니다. 우선 대외적으로 가장 널리 알려진 2세대 고 대역폭 메모리(HBM)을 탑재한 점을 꼽을 수 있습니다. 이미 라데온 Fury 시리즈가 소비자용 그래픽 카드 최초로 1세대 HBM을 탑재한 바 있으니 당연하다면 당연한 발전인 셈 입니다.
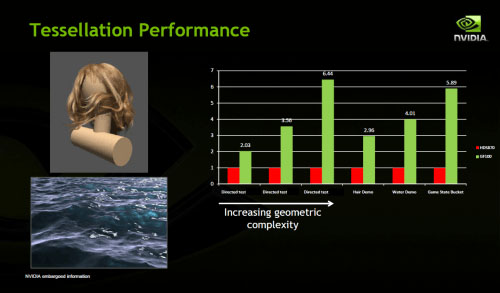
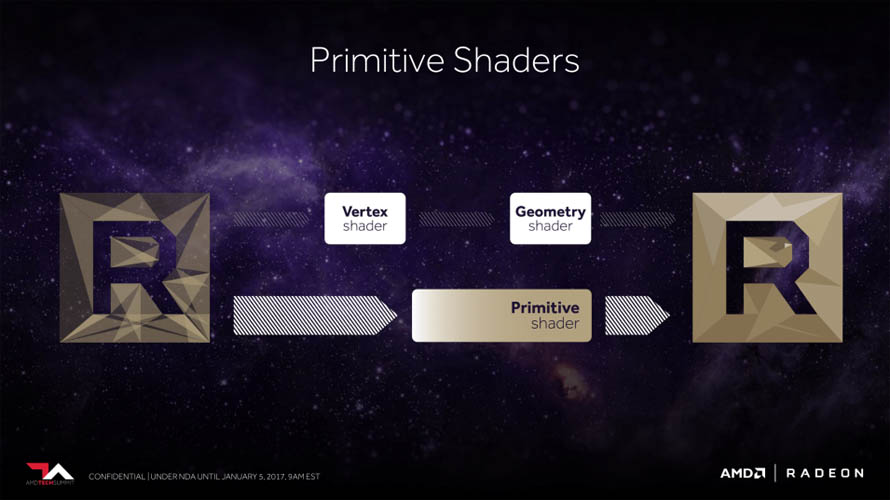
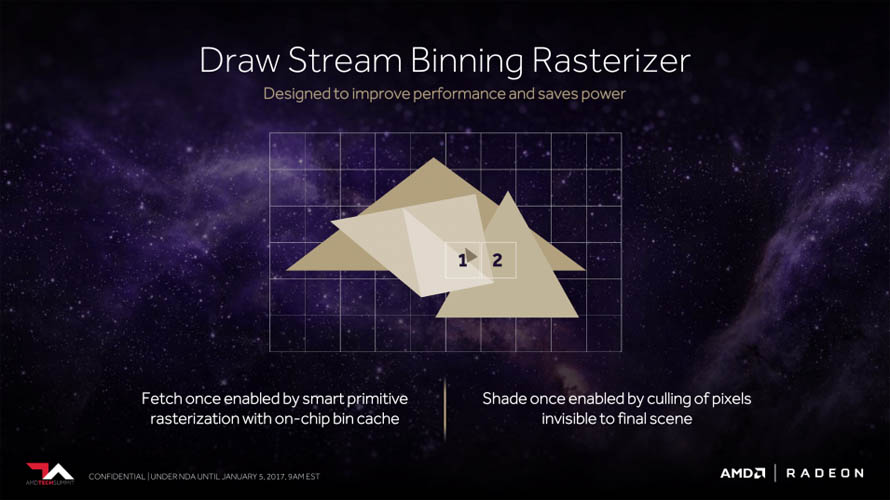
일반 소비자 입장에서 체감할만한 그래픽 컴퓨팅 요소로는 테셀레이션(Tessellation) 성능을 향상시킬 수 있도록 스케줄링 방식을 최적화(Intelligent Workgroup Distributor)하거나, 버텍스와 지오메트리 명령어를 한 스테이지에 끝낼 수 있는 프리미티브 셰이더(Primitive Shder) 추가, 경쟁사에서 먼저 적용한 타일 기반 렌더링(Draw Stream Binning Rasterizer) 도입이 확인되었습니다.
실제로 베가 아키텍처는 성능 외적으로 많은 면에서 기존 GPU 설계대비 차별화된 기능들이 대거 투입된 기념비적 라인업입니다. 우선 대외적으로 가장 널리 알려진 2세대 고 대역폭 메모리(HBM)을 탑재한 점을 꼽을 수 있습니다. 이미 라데온 Fury 시리즈가 소비자용 그래픽 카드 최초로 1세대 HBM을 탑재한 바 있으니 당연하다면 당연한 발전인 셈 입니다.
일반 소비자 입장에서 체감할만한 그래픽 컴퓨팅 요소로는 테셀레이션(Tessellation) 성능을 향상시킬 수 있도록 스케줄링 방식을 최적화(Intelligent Workgroup Distributor)하거나, 버텍스와 지오메트리 명령어를 한 스테이지에 끝낼 수 있는 프리미티브 셰이더(Primitive Shder) 추가, 경쟁사에서 먼저 적용한 타일 기반 렌더링(Draw Stream Binning Rasterizer) 도입이 확인되었습니다.
라데온 400 / 500 시리즈, 폴라리스
(2016년 6월, Polaris)
- 라데온 400 / 500 시리즈, 폴라리스
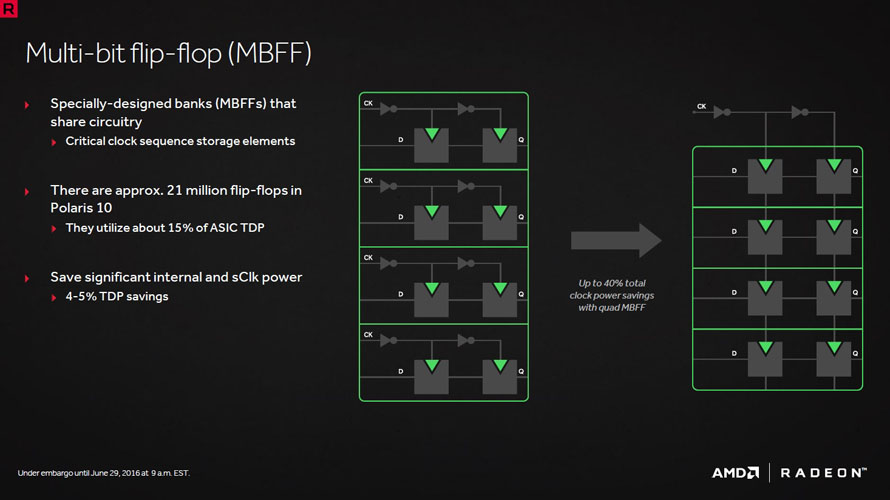
오랫동안 암흑기를 거친 AMD의 그래픽 사업부가 라데온 테크놀로지스 그룹(RTG, Radeon Technology Group)으로 분리된 뒤 처음으로 선보인 아키텍처가 바로 폴라리스입니다. 구조적으로는 GCN 아키텍처 기반의 명령어 세트 설계를 계승했지만, 14nm FinFET 공정으로 전환에 성공해 이전 세대 모델의 편입 없이 모든 라인업을 일신했습니다.
최초의 폴라리스는 두 가지 칩 디자인으로 출시되었고, 이후 최저가 모델을 위한 칩이 추가로 개발되었습니다. 중급기를 담당하는 폴라리스 10(20, 500 시리즈)은 최대 2304개의 스트리밍 프로세서를 내장한 라데온 RX 480(RX 580) 및 하위 모델로 2048개의 라데온 RX 470(RX 570) 이 출시되었으며, 중국 한정으로 1792개의 스트리밍 프로세서를 탑재한 RX 470D 모델이 출시된 전례가 있습니다.
폴라리스 12는 데스크탑 최저가 시장 및 노트북용으로 개발된 GPU 코어로 폴라리스 11처럼 수율 확보를 위해 최대 640개의 스트리밍 프로세서 중 512개를 사용하는 라데온 RX 550으로 출시되었습니다. 미세공정 수주처인 글로벌 파운드리의 14nm 공정이 LPE(Low Power Early)에서 LPP(Low Power Plus)로 전환되면서 핀펫(FinFET)의 접촉면적이 증가, 수율이 향상되면서 의미있는 클럭 상승분이 발생해 라데온 RX 400 시리즈에서 RX 500 시리즈로 업데이트 되었습니다.
최초의 폴라리스는 두 가지 칩 디자인으로 출시되었고, 이후 최저가 모델을 위한 칩이 추가로 개발되었습니다. 중급기를 담당하는 폴라리스 10(20, 500 시리즈)은 최대 2304개의 스트리밍 프로세서를 내장한 라데온 RX 480(RX 580) 및 하위 모델로 2048개의 라데온 RX 470(RX 570) 이 출시되었으며, 중국 한정으로 1792개의 스트리밍 프로세서를 탑재한 RX 470D 모델이 출시된 전례가 있습니다.
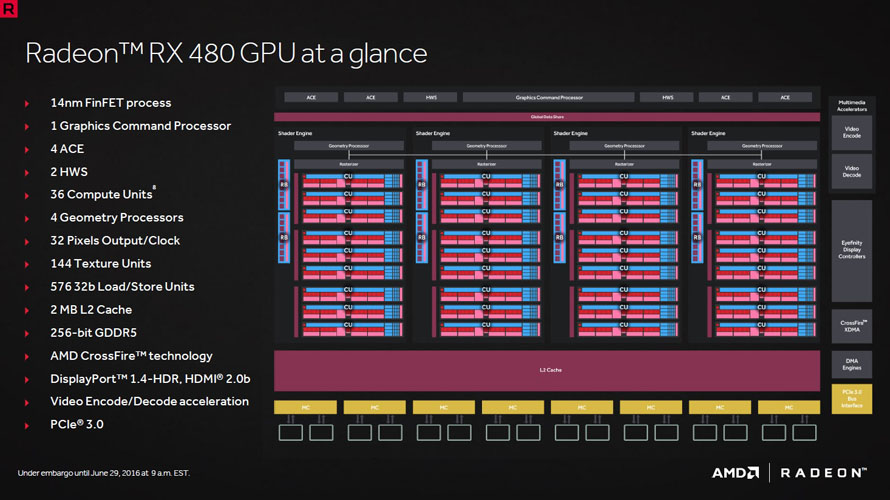
폴라리스 12는 데스크탑 최저가 시장 및 노트북용으로 개발된 GPU 코어로 폴라리스 11처럼 수율 확보를 위해 최대 640개의 스트리밍 프로세서 중 512개를 사용하는 라데온 RX 550으로 출시되었습니다. 미세공정 수주처인 글로벌 파운드리의 14nm 공정이 LPE(Low Power Early)에서 LPP(Low Power Plus)로 전환되면서 핀펫(FinFET)의 접촉면적이 증가, 수율이 향상되면서 의미있는 클럭 상승분이 발생해 라데온 RX 400 시리즈에서 RX 500 시리즈로 업데이트 되었습니다.


지포스 10 시리즈, 파스칼
(2016년 4월, Pascal)
- 지포스 10 시리즈, 파스칼
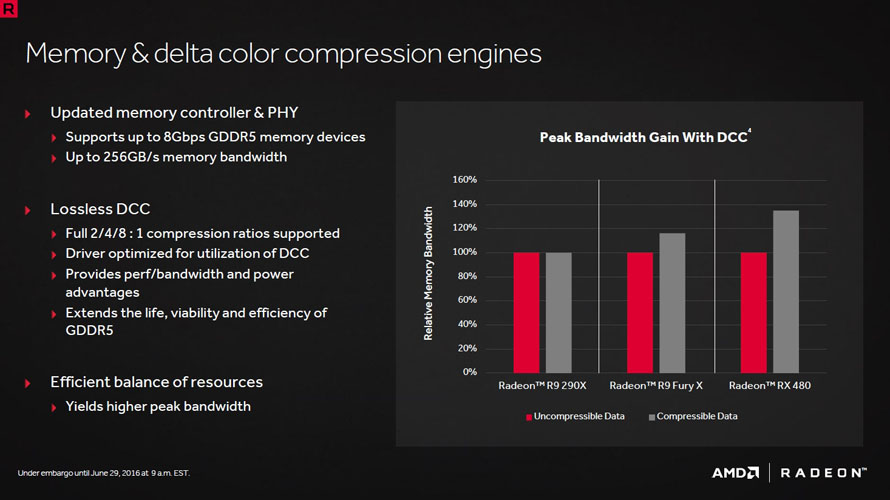
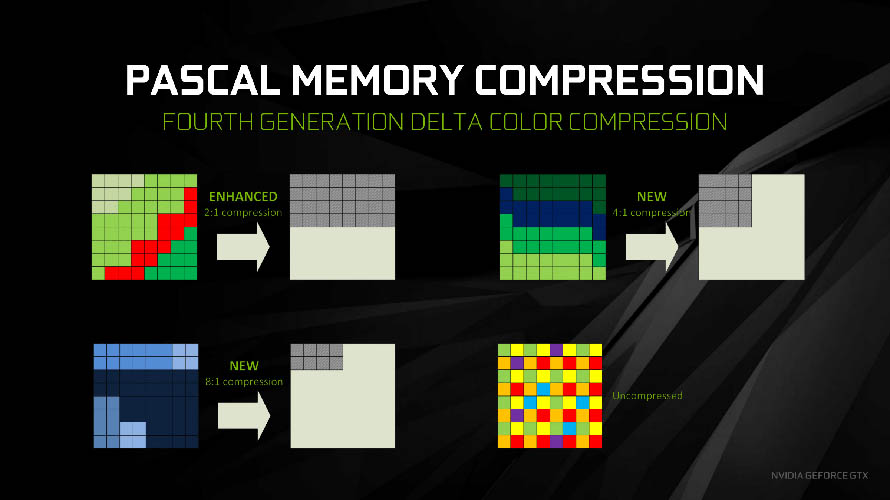
엔비디아 파스칼 아키텍처는 오랫동안 GPU 업계의 발목을 잡아온 28nm 공정에서 벗어나 16nm FinFET 공정으로 생산되는 차세대 그래픽 솔루션입니다. 순수 그래픽 성능과 직결되는 설계 특성으로는 VRAM과 통신하는 메모리 인터페이스를 개선하는 한편, 진보한 델타 컬러 압축기술로 대역폭 점유율을 절약하는데 힘 쓴 모습입니다.
또한 플래그십 라인업인 GTX 1080 / GTX 1080 Ti / TITAN X 모델들은 최초로 GDDR5X 메모리를 채택하기도 했습니다. 기존 GDDR5 메모리가 7~8Gbps에서 상한선에 도달한 것과 달리, GDDR5X는 10Gbps 이상의 유효 클럭을 제공해 고 대역폭 메모리(HBM) 기술이 성숙할 때 까지 교두보 역할을 하기에 충분한 성능을 제공해 줄 것으로 기대됩니다.
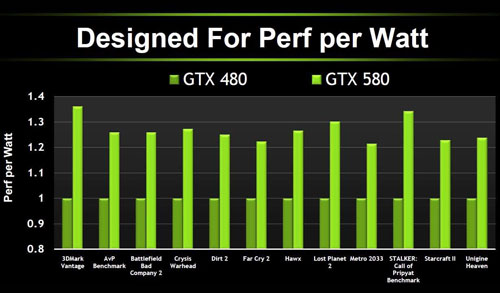
이번만큼은 경쟁사와 마찬가지로 실질적인 연산부인 스트리밍 멀티프로세서(SM) 구조는 맥스웰과 달라지지 않았기 때문에 클럭당 성능(IPC) 측면에서는 상술한 스케줄링 최적화 및 메모리 인터페이스 효율화 정책에 의한 상승분이 다수를 차지하며, 가시적으로 드러난 성능 향상폭은 신 공정 도입에 의한 폭발적인 최대 클럭 상승과 전력대비 성능 극대화의 공이 컸습니다.
또한 플래그십 라인업인 GTX 1080 / GTX 1080 Ti / TITAN X 모델들은 최초로 GDDR5X 메모리를 채택하기도 했습니다. 기존 GDDR5 메모리가 7~8Gbps에서 상한선에 도달한 것과 달리, GDDR5X는 10Gbps 이상의 유효 클럭을 제공해 고 대역폭 메모리(HBM) 기술이 성숙할 때 까지 교두보 역할을 하기에 충분한 성능을 제공해 줄 것으로 기대됩니다.

이번만큼은 경쟁사와 마찬가지로 실질적인 연산부인 스트리밍 멀티프로세서(SM) 구조는 맥스웰과 달라지지 않았기 때문에 클럭당 성능(IPC) 측면에서는 상술한 스케줄링 최적화 및 메모리 인터페이스 효율화 정책에 의한 상승분이 다수를 차지하며, 가시적으로 드러난 성능 향상폭은 신 공정 도입에 의한 폭발적인 최대 클럭 상승과 전력대비 성능 극대화의 공이 컸습니다.


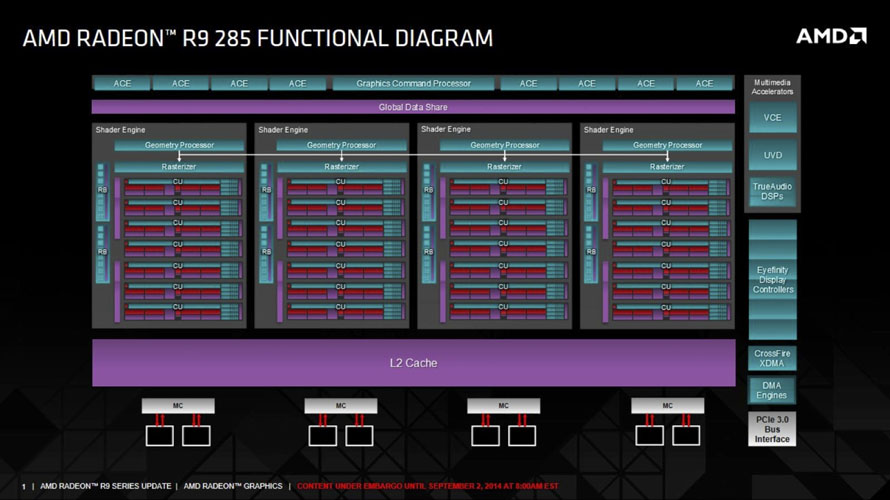
라데온 300 시리즈, 파이러츠 아일랜드
(2015년 6월, Pirates Islands)
- 라데온 300 시리즈, 파이러츠 아일랜드
중급기 AMD 라데온 R9 285 및 라데온 R9 380 시리즈로 통가(Tonga)가 먼저 출시된 후, 고 대역폭 메모리(HBM)를 지원하는 최상위 라인업 AMD 라데온 R9 Fury 시리즈로 피지(Fiji) 아키텍처가 발표되었습니다.
본격적으로 DirectX 12에 비동기 컴퓨트(Asynchronous Compute) 기능이 추가되면서 이를 강화시켜 줄 하드웨어 스케줄러를 탑재하고, 델타 컬러 압축(DCC) 기능을 도입해 그래픽 메모리를 효율적으로 활용하는데 주력한 모습입니다.
이후 라데온 R9 380 시리즈로 전환되면서 클럭 스피드가 향상되고 2048개의 스트리밍 프로세서를 탑재한 R9 380X 모델이 단종 수순을 밟은 타히티보다 높은 성능을 달성했으며, 최대 4GB GDDR5 메모리를 탑재한 사양이 경쟁 상대(2GB)에 비해 우위를 점하면서 쏠쏠한 인기를 누렸습니다.
피지 아키텍처의 경우 하와이 아키텍처만으로는 커버가 불가능했던 경쟁사의 최상위 라인업을 견제하기 위해 최신 기술을 접목한 설계로 많은 관심을 받았습니다. 비록 성능 경쟁에서 우위를 점하지는 못했지만 GDDR5 메모리 대신 HBM을 도입한 최초의 소비자용 그래픽 카드라는 타이틀을 차지했으며, 라데온 R9 Nano 모델은 가장 작은 하이엔드 그래픽 카드로 집중 조명을 받았습니다.
본격적으로 DirectX 12에 비동기 컴퓨트(Asynchronous Compute) 기능이 추가되면서 이를 강화시켜 줄 하드웨어 스케줄러를 탑재하고, 델타 컬러 압축(DCC) 기능을 도입해 그래픽 메모리를 효율적으로 활용하는데 주력한 모습입니다.

이후 라데온 R9 380 시리즈로 전환되면서 클럭 스피드가 향상되고 2048개의 스트리밍 프로세서를 탑재한 R9 380X 모델이 단종 수순을 밟은 타히티보다 높은 성능을 달성했으며, 최대 4GB GDDR5 메모리를 탑재한 사양이 경쟁 상대(2GB)에 비해 우위를 점하면서 쏠쏠한 인기를 누렸습니다.
피지 아키텍처의 경우 하와이 아키텍처만으로는 커버가 불가능했던 경쟁사의 최상위 라인업을 견제하기 위해 최신 기술을 접목한 설계로 많은 관심을 받았습니다. 비록 성능 경쟁에서 우위를 점하지는 못했지만 GDDR5 메모리 대신 HBM을 도입한 최초의 소비자용 그래픽 카드라는 타이틀을 차지했으며, 라데온 R9 Nano 모델은 가장 작은 하이엔드 그래픽 카드로 집중 조명을 받았습니다.



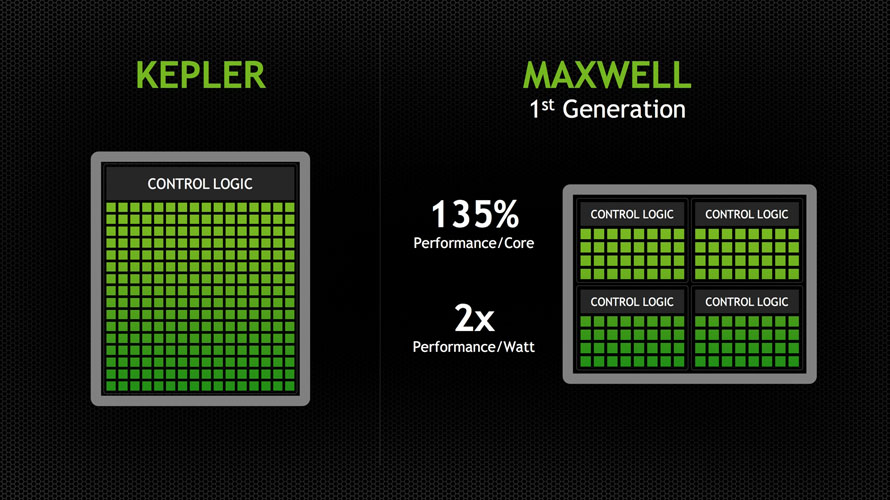
지포스 900 / 750 시리즈, 맥스웰
(2014년 9월, Maxwell)
- 지포스 900 / 750 시리즈, 맥스웰
3세대 폴리모프 엔진이 32개의 CUDA 코어로 구성된 모듈 4개를 관리하는 SMM 명령어 세트 설계(128 CUDA Cores)를 최소단위로 구축됩니다. 스페셜 피쳐 유닛(SFU) 하나당 4개의 CUDA 코어가 할당되어 GF100/110에서 보여준 1:8 비율보다 높은 밀도의 SM 구성을 갖췄으며, 케플러 아키텍처보다 배정밀도 유닛 비율을 더 줄여(1/32) 그래픽 카드로서의 효율성을 한층 더 향상시켰습니다.
*단, 최초의 맥스웰 아키텍처는 지포스 GTX 750 시리즈로 출시되어 2세대 폴리모프 엔진을 탑재해 DirectX 12(FL11.0) / HDMI 1.4a 포트까지 지원합니다. 나머지 맥스웰 아키텍처 기반 지포스 GTX 900 시리즈는 DirectX 12(FL12.1) / HDMI 2.0 포트를 지원합니다.
맥스웰 이후 아키텍처들이 명령어 세트 설계의 명칭을 SM(스트리밍 멀티프로세서)으로 변경하면서 사실상 SM 구조에 기반한 그래픽 명령어 세트 설계의 최종 형태로 여겨지고 있습니다. 이에 따라 일반 연산으로는 한계가 뚜렷한 특정 기능들을 하드웨어 레벨의 GPU 병렬 연산으로 가속하는 전용 명령어 세트를 추가하는 형태로 바뀌게 됩니다.
*단, 최초의 맥스웰 아키텍처는 지포스 GTX 750 시리즈로 출시되어 2세대 폴리모프 엔진을 탑재해 DirectX 12(FL11.0) / HDMI 1.4a 포트까지 지원합니다. 나머지 맥스웰 아키텍처 기반 지포스 GTX 900 시리즈는 DirectX 12(FL12.1) / HDMI 2.0 포트를 지원합니다.

맥스웰 이후 아키텍처들이 명령어 세트 설계의 명칭을 SM(스트리밍 멀티프로세서)으로 변경하면서 사실상 SM 구조에 기반한 그래픽 명령어 세트 설계의 최종 형태로 여겨지고 있습니다. 이에 따라 일반 연산으로는 한계가 뚜렷한 특정 기능들을 하드웨어 레벨의 GPU 병렬 연산으로 가속하는 전용 명령어 세트를 추가하는 형태로 바뀌게 됩니다.
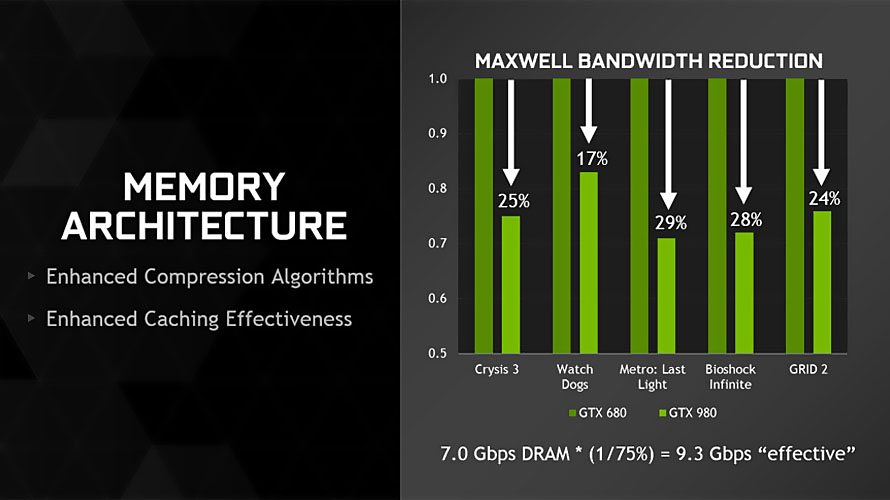
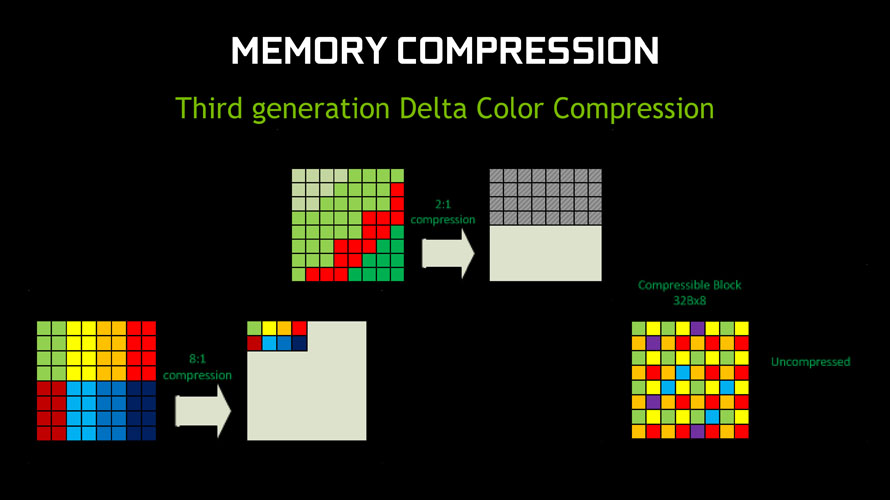

라데온 200 시리즈, 볼케닉 아일랜드
(2013년 10월, Volcanic Islands)
- 라데온 200 시리즈, 볼케닉 아일랜드
중~보급기인 AMD 라데온 HD 7790으로 보네어(Bonaire)가 먼저 출시된 후, 최상위 모델인 AMD 라데온 R9 290 시리즈로 하와이(Hawaii) 아키텍처가 모습을 드러냈습니다.
DP(DisplayPort) 및 HDMI 포트가 대중화되면서 GPU에 내장된 오디오 코덱을 보다 유용하게 활용할 수 있도록 AMD 트루오디오(TrueAudio) 음장효과가 추가되었고, ACE 스케줄러를 강화시켜 연산 효율을 강화시킨 것이 주요 특징입니다.
하와이는 최대 2816개, 보네어는 최대 896개의 스트리밍 프로세서를 탑재했습니다. 또한 두 제품 모두 Rx 200 시리즈에서 Rx 300 시리즈로 전환되면서 GDDR5 그래픽 메모리 용량을 두 배로 늘려 4K 초고해상도나 가상현실과 같은 차세대 디스플레이 환경에 대응하는 모습을 보여주기도 했습니다.
DP(DisplayPort) 및 HDMI 포트가 대중화되면서 GPU에 내장된 오디오 코덱을 보다 유용하게 활용할 수 있도록 AMD 트루오디오(TrueAudio) 음장효과가 추가되었고, ACE 스케줄러를 강화시켜 연산 효율을 강화시킨 것이 주요 특징입니다.

하와이는 최대 2816개, 보네어는 최대 896개의 스트리밍 프로세서를 탑재했습니다. 또한 두 제품 모두 Rx 200 시리즈에서 Rx 300 시리즈로 전환되면서 GDDR5 그래픽 메모리 용량을 두 배로 늘려 4K 초고해상도나 가상현실과 같은 차세대 디스플레이 환경에 대응하는 모습을 보여주기도 했습니다.
지포스 600 / 700 시리즈, 케플러
(2012년 3월, Kepler)
- 지포스 600 / 700 시리즈, 케플러
혁신적인 구조였지만 발열과 전력 소비량으로 인해 결과가 썩 좋진 않았던 페르미의 계륵 포인트로 꼽힌 배정밀도(DP) 연산을 담당할 별개의 유닛을 만들어 1/24 수준으로 줄였습니다. 이 때 부터 분야별로 최적화 방법을 달리하되 통합 설계를 추구한 경쟁사와 달리, 주력 연산처에 따라 명확하게 제품군을 분리시켜 자원 비율을 조절하며 GPU 코어를 설계하는 방향으로 노선을 정했다고 볼 수 있습니다.
2세대 폴리모프 엔진에 192개의 CUDA 코어로 구성된 SMX 명령어 세트 설계를 최소 단위로 가지며, 엔비디아에서 공개한 자료에 따르면 케플러 아키텍처는 GF104/114 기반을 개량한 것에 가깝습니다. 스페셜 피쳐 유닛(SFU)과 CUDA 코어의 비율이 1:6을 이루도록 구성되었기 때문인데 로드/스토어 및 SFU를 공유 자원으로 활용하면서 하나의 커다란 로직으로 분류되었지만, 본질적으로는 SM(48) 4개를 통합하여 효율적인 병렬성을 추구한 구조라고 볼 수 있습니다.
다만 케플러 라인업부터 GTX TITAN 이라는 새로운 플래그십 라인업을 출시하면서 처음이자 마지막으로 예외를 두었는데, 테슬라(TESLA) 라인업에서만 허용된 배정밀도(DP) 유닛을 모두 탑재해서 출시한 것 입니다. 케플러 이후 아키텍처 기반 GTX TITAN 들은 배정밀도 유닛이 제한된 채로 출시되었습니다.
2세대 폴리모프 엔진에 192개의 CUDA 코어로 구성된 SMX 명령어 세트 설계를 최소 단위로 가지며, 엔비디아에서 공개한 자료에 따르면 케플러 아키텍처는 GF104/114 기반을 개량한 것에 가깝습니다. 스페셜 피쳐 유닛(SFU)과 CUDA 코어의 비율이 1:6을 이루도록 구성되었기 때문인데 로드/스토어 및 SFU를 공유 자원으로 활용하면서 하나의 커다란 로직으로 분류되었지만, 본질적으로는 SM(48) 4개를 통합하여 효율적인 병렬성을 추구한 구조라고 볼 수 있습니다.
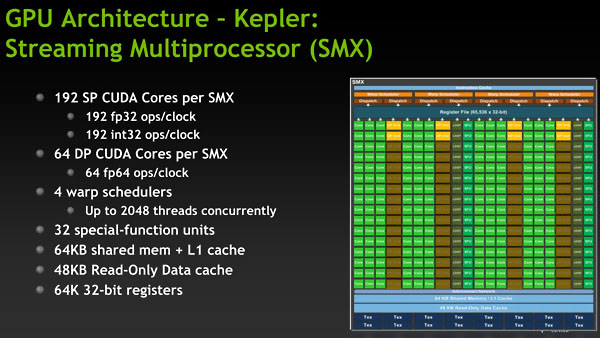
다만 케플러 라인업부터 GTX TITAN 이라는 새로운 플래그십 라인업을 출시하면서 처음이자 마지막으로 예외를 두었는데, 테슬라(TESLA) 라인업에서만 허용된 배정밀도(DP) 유닛을 모두 탑재해서 출시한 것 입니다. 케플러 이후 아키텍처 기반 GTX TITAN 들은 배정밀도 유닛이 제한된 채로 출시되었습니다.



라데온 HD 7000 시리즈, 서던 아일랜드
(2012년 1월, Southern Islands)
- 라데온 HD 7000 시리즈, 서던 아일랜드
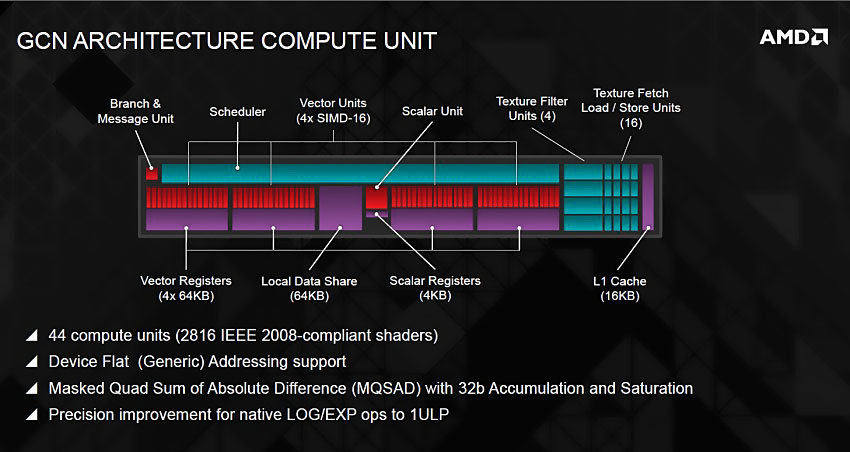
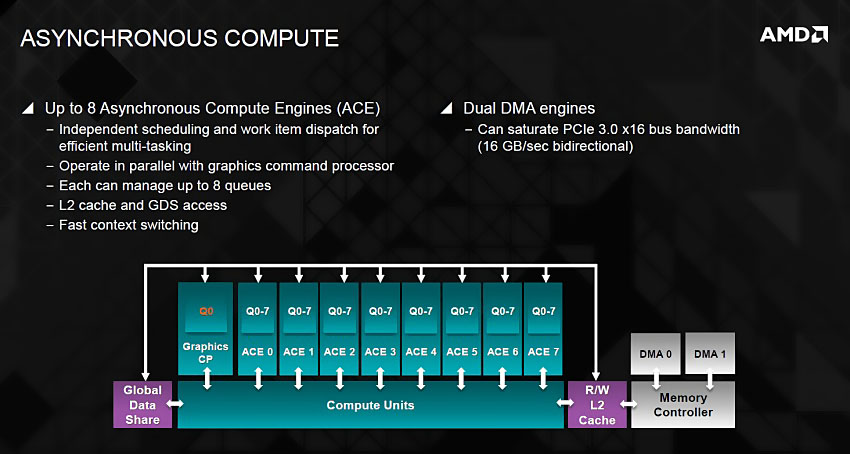
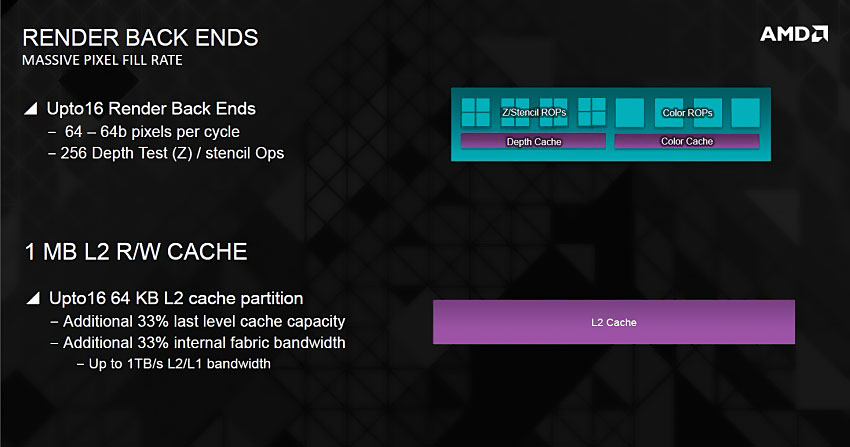
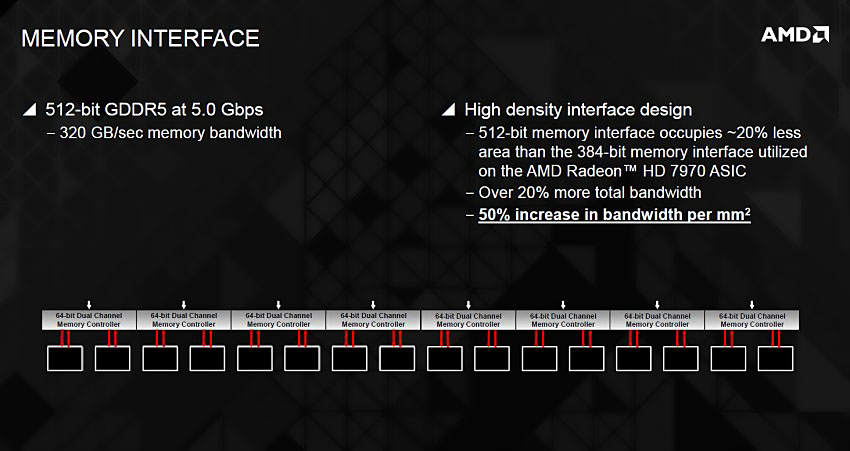
그래픽 코어 넥스트(GCN) 아키텍처는 16개의 벡터 산술 연산자로 구성된 SIMD(Single Instruction Multi Data) 유닛 4개와 스칼라 유닛 1개 묶음으로 하나의 컴퓨트 유닛(CU)을 이루며, 이를 비동기 컴퓨트 엔진(ACE, Asynchronous Compute Engine)이 관리하는 방식입니다.
라데온 GPU 코어로는 최초로 VLIW 명령어 세트 대신 RISC 명령어 세트를 도입하는 거대한 변화를 성공적으로 이행한 기념비적인 아키텍처라고 볼 수 있겠습니다.
출시 당시에는 DirectX 11 및 OpenGL 4.2 / OpenCL™ 1.2 버전과 하드웨어 테셀레이션 유닛을 탑재한 것이 주요 특징이었지만 시간이 지나며 DirectX 12(Feature Level 11.1) 및 OpenGL 4.5로 확장되었으며, 독자 API 맨틀(Mantle)에서 파생된 벌칸(Vulkan) API와 비동기 셰이더(Asynchronous Compute) 기능을 추가로 지원합니다.
라데온 GPU 코어로는 최초로 VLIW 명령어 세트 대신 RISC 명령어 세트를 도입하는 거대한 변화를 성공적으로 이행한 기념비적인 아키텍처라고 볼 수 있겠습니다.
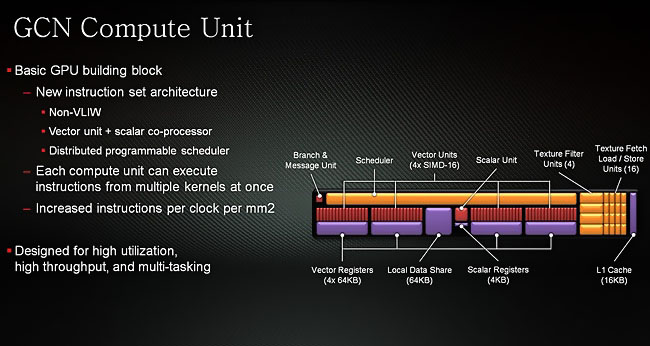
출시 당시에는 DirectX 11 및 OpenGL 4.2 / OpenCL™ 1.2 버전과 하드웨어 테셀레이션 유닛을 탑재한 것이 주요 특징이었지만 시간이 지나며 DirectX 12(Feature Level 11.1) 및 OpenGL 4.5로 확장되었으며, 독자 API 맨틀(Mantle)에서 파생된 벌칸(Vulkan) API와 비동기 셰이더(Asynchronous Compute) 기능을 추가로 지원합니다.




지포스 400 / 500 시리즈, 페르미
(2010년 4월, Fermi)
- 지포스 400 / 500 시리즈, 페르미
32개의 CUDA 코어로 구성된 명령어 세트 설계 SM(Streaming Multiprocessor)가 최초로 구색을 갖춘 모델입니다. TSMC의 40nm 미세공정과 GDDR5 메모리를 투입해 성능상 우위를 되찾았지만, 두 개의 ALU로 배정밀도 연산을 실시하도록 설계되어 뛰어난 성능을 발휘했음에도 불구하고 당시 불안정했던 미세공정과 자원 분배 효율 문제로 발열과 전력 소비량이 과도하게 늘어나는 경향을 보였습니다.
지포스 GTX 480 / GTX 470 / GTX 465에 이르는 상위 라인업을 구축한 GF100 코어에서 이러한 문제가 불거지자, 중급기용으로 설계하던 GF104 코어는 아예 배정밀도 연산을 겸하는 지정 CUDA 코어 16개(DP 연산에 4개의 코어 사용, 4x4)를 추가로 집어넣어 단정밀도 연산을 우선하는 16+32 CUDA 코어로 구성된 스트리밍 멀티프로세서를 투입합니다. 이러한 구조는 GF11x 코어까지 이어집니다.
512개(GTX 580) / 480개(GTX 480 & GTX 570) / 448개(GTX 470 & GTX 560 Ti) / 352개(GTX 465) 까지 GF100-GF110 코어로 구성되었으며, 384개(GTX 560) / 336개(GTX 460 & GTX 560) / 288개(GTX 460 SE & GTX 560 SE) 가 GF104-GF114 코어, 192개(GTS 450 & GTX 550 Ti) GF106-GF116 코어로 제품군을 선보였으며, 같은 모델명이라도 ROP 개수와 클럭 스피드를 달리한 제품들이 있습니다.
출시 초기엔 DirectX 11, OpenGL 4.0을 지원했으며, 드라이버 업데이트를 통해 DirectX 12(Feature Level 11.0), OpenGL 4.5, OpenCL 1.1까지 지원할 수 있도록 확장되었습니다. 엔비디아에서 출시한 GPU 중 최초로 DirectX 12를 정식 지원하는 그래픽 카드로 남은 기념비적인 모델이라고 할 수 있겠습니다.
지포스 GTX 480 / GTX 470 / GTX 465에 이르는 상위 라인업을 구축한 GF100 코어에서 이러한 문제가 불거지자, 중급기용으로 설계하던 GF104 코어는 아예 배정밀도 연산을 겸하는 지정 CUDA 코어 16개(DP 연산에 4개의 코어 사용, 4x4)를 추가로 집어넣어 단정밀도 연산을 우선하는 16+32 CUDA 코어로 구성된 스트리밍 멀티프로세서를 투입합니다. 이러한 구조는 GF11x 코어까지 이어집니다.

512개(GTX 580) / 480개(GTX 480 & GTX 570) / 448개(GTX 470 & GTX 560 Ti) / 352개(GTX 465) 까지 GF100-GF110 코어로 구성되었으며, 384개(GTX 560) / 336개(GTX 460 & GTX 560) / 288개(GTX 460 SE & GTX 560 SE) 가 GF104-GF114 코어, 192개(GTS 450 & GTX 550 Ti) GF106-GF116 코어로 제품군을 선보였으며, 같은 모델명이라도 ROP 개수와 클럭 스피드를 달리한 제품들이 있습니다.
출시 초기엔 DirectX 11, OpenGL 4.0을 지원했으며, 드라이버 업데이트를 통해 DirectX 12(Feature Level 11.0), OpenGL 4.5, OpenCL 1.1까지 지원할 수 있도록 확장되었습니다. 엔비디아에서 출시한 GPU 중 최초로 DirectX 12를 정식 지원하는 그래픽 카드로 남은 기념비적인 모델이라고 할 수 있겠습니다.